How to Evaluate Machine Learning Algorithms
Originally published at https://www.niit.com/india/.
Machine learning (ML) is the study of computer algorithms that automatically enhance functions through experience and data use. It is a component of artificial intelligence. Machine learning algorithms are programs (math and logic) that modify themselves to perform satisfactorily as they are disclosed to more data. The “learning” aspect of machine learning implies that the programs change how they process data over time, much as humans change how they process data by learning. Machine learning algorithms are used in a vast variety of applications, such as in medicine, email filtering, speech distinction, and computer vision, where it is tough to develop traditional algorithms to perform the needed duties.
If you are willing to learn machine learning then, do check out the Machine Learning (Part-Time) course and Machine Learning (Full Time) course offered at NIIT.
Different learning styles in machine learning algorithms
1. Supervised Learning
This algorithm contains a target/outcome variable (or dependent variable) that is foreseen from a given set of forecasters (independent variables). Using this set of variables, we produce a function that maps inputs to requested outputs. The training process proceeds until the model accomplishes the desired level of accuracy on the training data.
Examples of Supervised algorithms include Logistic Regression and the Back Propagation Neural Network.
2. Unsupervised Learning
In this algorithm, we work without a target or outcome variable to predict / estimate. It is used for congregating populations in various groups, which is widely used for segmenting customers in different groups for a particular intervention.
Example algorithms include the Apriori algorithm and K-Means.
3. Reinvestment Learning
In this type of algorithm, the machine is instructed to make specific decisions. It follows the process where the machine is exposed to a setting where it trains itself repeatedly using the trial and error method. In this process, the machine learns from experience and tries to apprehend the best logical knowledge to make accurate business decisions.
Example of Reinforcement Learning: Markov Decision Process.
Commonly Used Machine Learning Algorithms
1. Linear Regression
It is used to evaluate actual values (cost of products, number of calls, total sales, etc.) based on a constant variable(s). The process is to establish a relationship between independent and dependent variables by fitting the suitable line. This suitable fit line is known as the regression line and is represented by a linear equation.
Y= a *X + b.
In this equation:
Y — Dependent Variable
a — Slope
X — Independent variable
b — Intercept
These coefficients a and b are concluded based on minimizing the sum of squared difference of distance between data points and regression line.

2. Logistic Regression
It is used to calculate distinct values (Binary values like 0/1, yes/no, true/false) based on a given set of the independent variable(s). In other words, it foresees the probability of an event by fitting data to a logit function. Hence, it is also known as logit regression. Since it foresees the probability, its output values lie between 0 and 1 (as expected).
Coming to the math, the log odds of the outcome is designed as a linear combination of the predictor variables.

Above, p represents the probability of the existence of a characteristic of interest. It uses the method to maximize the probability of observing the sample values rather than minimizing the sum of squared errors (like in ordinary regression).
R CODE

3. Decision Tree
This algorithm is a type of supervised learning algorithm that is mainly used for classifying problems. The method is suitable for both categorical and continuous dependent variables. In this algorithm, the process of splitting the population into two or more homogeneous sets is used. This is accomplished based on the most significant attributes/ independent variables to make as distinct groups as feasible.
To divide the population into different heterogeneous groups, it uses various techniques such as Gini, Information Gain, Chi-square, Entropy, etc.
R CODE

4. kNN (k- Nearest Neighbors)
K- nearest neighbors is a simple algorithm that carries all available cases and categories, new cases by a majority vote of its k neighbors. It is used for both classification and regression, and in both cases, the input contains the k closest training measures in the data set. The outcome depends on whether k-NN is used for classification or regression.
In k-NN classification, the outcome is a class membership. K is a positive integer, normally small. If k = 1, then the object is simply entrusted to the class of that single nearest neighbor.
In k-NN regression, the outcome is the property value for the object. This value is considered as the average of the values of k nearest neighbors.
R CODE

5. Naive Bayes
This classification technique is based on Bayes’ theorem with an assumption of independence between predictors. In reasonable terms, a Naive Bayes classifier determines that the presence of a specific feature in a class is irrelevant to the presence of any other feature.
The Naive Bayesian model is simple to build and specifically useful for very large data sets. Along with simplicity, Naive Bayes is known to outshine even highly sophisticated classification methods.
Bayes theorem allows a way of calculating posterior probability P(c|x) from P(c), P(x), and P(x|c). Look at the equation below:

Here,
- P(c|x) is the posterior probability of class (target) given predictor (attribute).
- P(c) is the prior probability of class.
- P(x|c) is the likelihood which is the probability of the predictor given class.
- P(x) is the prior probability of the predictor.
R CODE

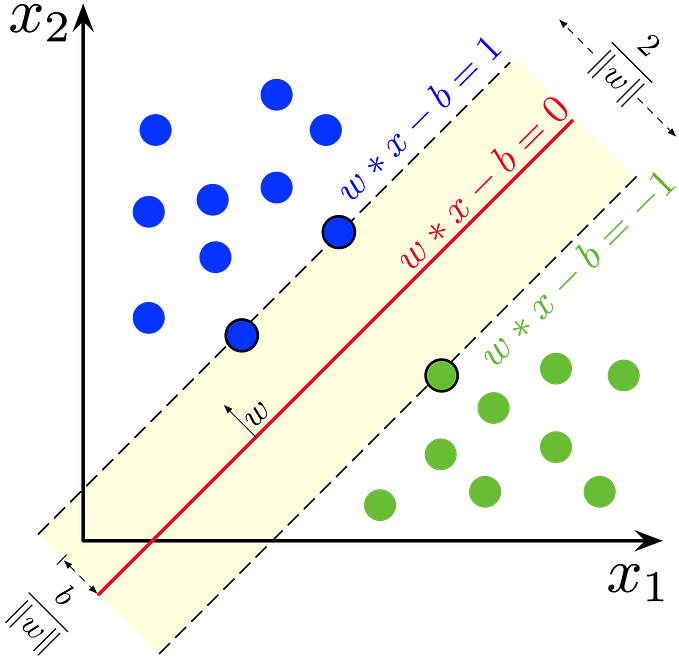
6. SVM (Support Vector Machine)
In this algorithm, we plan each data item as a point in n-dimensional space (where n is the number of features we have). Here, the value of each feature is the value of a particular coordinate. It is a classification method.
R CODE

Conclusion
In today’s world, where almost all manual tasks are being handled automatically, the definition of manual is evolving. Machine Learning algorithms enable computers to perform any given tasks like playing chess, perform surgeries, more smartly. Choosing the accurate machine learning algorithm depends on various factors including the size of the data, quality, and multiplicity, as well as what your clients want to develop from that data. Therefore, choosing the right algorithm is a sum of all the combinations of business needs, specification, investigation, and, of course, time availability.
Like reading about machine learning? Head over to our Knowledge Centre and explore deep-set content on emerging technologies like data science cybersecurity, cloud computing, 5G, and the Internet of Things.